Memory (2.X)
References:
A. Nayani, M. Gorman, R.S. de Castro,
"Memory management in Linux",
Linux Kernel Documentatin Project (2002)
J. Plusquellic, "CMPE 310: system design and programming"
http://www.csee.umbc.edu/~plusquel/310/
Memory is a crucial resource and its management is an important task.
It begins with memory detection at setup, when the kernel has not been
uncompressed yet. The setup.S code tries to detect the amount of memory
present on the system in three different ways: with the instruction e820,
with the instruction e801, and with the instruction 88.
Paging allows the programs to use virtual addresses,
because access to memory goes through
a translation procedure of the address.
Briefly an address is split in pieces; the first piece is an
offset in the main page (page global directory, pgd). The entry at
that offset points to the location of the next page directory,
whose entry is indiced by the second piece of the address.
And so on, until the second to the last piece, which is the offset
of the entry in the last page directory (the page table entries).
This entry points to a memory page, and the last piece of the address
is the offset in this page.
On i386 paging is controlled by the microprocessor control registers
31 12 11 10 9 8 7 6 5 4 3 2 1 0
CR0 PG CD NV AM WP NE ET TS EM MP PE
CR1 < reserved >
CR2 < most recent page faulting linear address >
CR3 < page global dir address > PCD PWT
CR4 MCE PSE DE TSD PVI VME
PE = protection enable: if set, execute in protected mode
MP = monitor coprocessor: if set, the CPU tests TS flags when executing WAIT
EM = emulation: if set, the CPU signal exeption 7 when executing ESC
TS = task switched, set at every task switch, and tested while interpreting coprocessor
instructions
ET = extension type (type of coprocessor)
NE =
PG = paging: if set, enable paging
Pages are aligned on 4KB boundary, therefore the lowest 12 bits of the
addresses of the pages (the entries in the varous page tables) are
not used to find the page in memory. These bits are used as flags to
describe the status of the page:
bit-0 (P) present
bit-1 (W) writable
bit-2 (U) user defined
bit-3 (PWT) write through
bit-4 (PCD) cache disable
bit-5 (A) accessed
bit-6 (D) dirty
Segmentation is the mechanism to describe access rights to memory regions.
Segments are interpreted differently in protected mode and in real mode.
The segment registers (DS, CS, etc.) contain the index of the segment
descriptor (entry in the descriptor table). This contains information
about the segment: base address, length, access rights.
Linux on i386 uses a flat memory model with four segment
descriptors (besides a few others),
two for the kernel (code+data) and two for user processes (code+data),
each spanning the full 4 GB (these are loaded by the setup code).
The setup code activates paging with two provisional pages, pg0 at 0x0010.2000
and pg1 at 0x0010.3000. The page global directory is swapper_pg_dir
(compiled at address 0x0010.1000) and is initialized with two entries for
each of the two pages: the first allows to translate virtual addresses
which coincide with the physical addresss, the second for virtual addresses
offseted by PAGE_OFFSET = 0xC000.0000 (3GB)
These two page tables allow to map the first 8MB of memory, which is
enough for the booting stage.
Then the kernel fills the array
e820 with the memory information
retrieved by the setup code, and finds the maximum page frame number
(ie, the maximum physical page index).
Then it goes through a check for high memory (over 896MB or specified on the
command line). In this step the following variables are set:
- start_pfn, first page frame number, just after the kernel,
ie, the page frame number of the physical address __end
- max_pfn, maximum number of a page frame in e820
- max_low_pfn, maximum number of a page frame in low memory.
It coincides with max_pfn if there is no high memory
- highmem_pages, number of pages in high memory
- highend_pfn, last page frame number of high memory
(rounded up)
Now the kernel initializes the bootmemory allocator.
The struct bootmem_data is compiled statically in the kernel,
and points to a bitmap of used/free pages. This bitmap is set immediately
after the kernel and is initialized with all pages marked "used".
The kernel scans the array e820 and clear the bits of the pages that
can be used, then sets the bits for the pages used by the kernel
(between 1MB and __end) and the bitmap itself.
Now it is time to setup the pages
(function paging_init(), in arch/i386/mm/init.c ).
The swapper_pg_dir is initialized, and the pages for the page middle directory
(pmd) and page table (pte) are allocated with the bootmemory allocator
and properly initialized. If there is high memory the mapping for it
(kmap) is also set up.
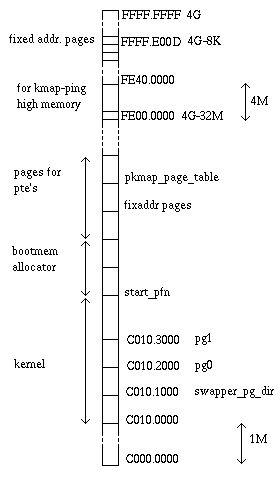 pagetable_init()
pagetable_init() sets up the pagetables.
The first 8 MB are mapped into pages in head.S.
The base page directory is the page
swapper_pg_dir.
For each entry in the PGD from PAGE_OFFSET to the virtual address
of the last physical page frame (therefore for each
entry in the kernel virtual address space) prepare the pages.
If the CPU has PSE (page size extension) use 4MB pages:
set the entry value to
the physical address (
__pa) of the entry virtual address,
plus some flags.
In other words entry 0x300, which corresponds to the virtual address
0xc000.0000, is assigned value 0x0. Entry 0x301 (virtual 0xc040.0000)
is assigned 0x0040.0000.
Otherwise a PTE page is allocated with
alloc_bootmem_low_pages
and each entry in the PTE is assigned the physical address of the virtual
address
pgd * PGDIR_SIZE + pte * PAGE_SIZE; finally the PGD entry
is assigned the physical address of the PTE page.
For example the entries of the first PTE are assigned addresses
0x0040.0000, 0x0040.1000, etc.
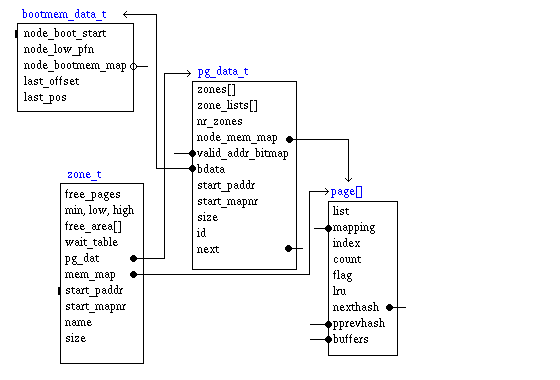
mem_map is a sparse array defind in memory.c and initialized
in numa.c to (mem_map_t *)PAGE_OFFSET. In other words the global mem_map
is virtual address 0xc000.0000, ie, physical address 0x0.
The memory is subdivided in uniform regions (nodes).
Each node can have up to three zones, DMA, NORMAL, and HIGH.
A node is described by the
pd_data_t struct, which contains inside
the array of its zones,
zone_t, the pointer to the portion
of
mem_map for this node, and the bitmap of usable/unusable pages.
The struct
zone_t contains
- the counter of free pages
- various watermark limits (min, low, high)
- the wait_queue_head for processes waiting for pages
- the memory map pointer to the mem_map portion of the zone
- starting physical address
- stating map number, ie, index in mem_map
- total size of physical memory in the zone
The struct page is rather short, 64 bytes (2**6).
Each 4KB (2**12) page contains 2**6 struct page's, which map 256KB
(2**18). 1 MB, containing 256 pages, therefore maps 64MB (2**26).
Basically, with 4KB pages, 1/64 of the physical memory contains
the memory map. With bigger pages the fraction of memory devoted to the
memory map is smaller.
The new pages are activated setting
the address of swapper_pg_dir into cr3.
Memory Addresses
Linear addresses are mapped to the physical memory with a three-level
page directory/table mechanism: the global page directory,
the middle page directory and the page table. On some architectures
(such as the i386 without PAE) only two levels are used and the middle
directory is "folded over" the global directory with a C preprocessor
macro trick. The figure below shows this case.
Addresses and address translations are defined in the header file
include/asm-i386/page.h
| PAGE_SHIFT | | 12 |
| PAGE_SIZE | 0x1 << PAGE_SHIFT | 0x1000 |
| PAGE_MASK | ~(PAGE_SIZE-1) | 0x ffff f000 |
| PAGE_OFFSET | | 0x C000 0000 |
| __pa(x) | x - PAGE_OFFSET | physical address |
| __va(x) | x + PAGE_OFFSET | virtual address |
| virt_to_page(x) | (x - PAGE_OFFSET)>>PAGE_SHIFT
| page index |
| PGDIR_SHIFT | | 22 or 30 |
| PMDIR_SHIFT | | 22 or 21 |
| PTRS_PER_PGD | | 1024 or 4 |
| PTRS_PER_PMD | | 1 or 512 |
| PTRS_PER_PTE | | 1024 or 512 |
The types
pte_t,
pmd_t,
pgd_t and
pgprot_t
are just struct containing the long
pte,
pmd,
pgd
and
pgprot, respectively.
The
__xxx(x) are casts to the proper type.
The
xxx_val(x) defines return the long inside the struct.
The defines
set_xxx assign a value at the entry pointed to.
The
__xxx_offset return the offset of the address in the table.
The
xxx_offset return the entry for the address in the table.
__pgd(x) = (pgd_t)(x)
__pmd(x) = (pmd_t)(x)
__pte(x) = (pte_t)(x)
pgd_val(x) = (x).pgd
pmd_val(x) = (x).pmd
pte_val(x) = (x).pte
set_pgd( pgdptr, pgdval ) { *pgdptr = pgdval; }
set_pmd( pmdptr, pmdval ) { *pmdptr = pmdval; }
set_pte( pteptr, pteval ) { *pteptr = pteval; }
pgd_page( pgd ) = __va( pgd & PAGE_MASK )
pmd_page( pmd ) = __va( pmd & PAGE_MASK )
__mk_pte(page, prot) = __pte( (page<<PAGE_SHIFT) | prot )
__pgd_offset( addr ) = (addr >> PGDIR_SHIFT) & (PTRS_PER_PGD - 1)
__pmd_offset( addr ) = (addr >> PMD_SHIFT) & (PTRS_PER_PMD - 1)
__pte_offset( addr ) = (addr >> PAGE_SHIFT) & (PTRS_PER_PTE - 1)
pgd_index( addr ) = __pgd_offset( addr )
pgd_offset(mm, addr) = mm->pgd + pgd_index( addr )
pmd_offset(dir, addr) = (pmd_t*)dir
pte_offset(dir, addr) = pmd_page( dir ) + __pte_offset( addr )
VMALLOC_VMADDR(x) = x
pgd_none, pmd_none, pte_none check if the entry does not refer
to a pmd, a pte or a page respectively.
The analogous xxx_present test the the entry referred to is present.
pmd_alloc(mm, pgd, addr) allocates a PMD (pmd_alloc_one) for the
given addr and mm_struct, and return the pmd_offset of addr in the pgd
(which is pgd itself considered as a pmd_t *).
This should never be called on i386 as pmd_alloc_one() is BUG().
The functions pgd_free, pmd_free, pte_free are used to free
the corresponding structure.
For i386 the first calls free_page with the pgd as address
(if PAE is not enabled).
pte_free puts the pte on the pte_quicklist.
The pgd_clear function is empty.
pmd_free is empty.
pmd_clear(pmd) and pte_clear(pte)
assign 0 to their arguments.
free_page(addr) (which is defined as free_pages(addr, 0),
ie, a page of order=0, in linux/mm.h), gets the page pointer from the
virtual address (virt_to_page(addr)), performs some
checks, and returns the page to the buddy allocator of the relevant zone.
(See mm/page_alloc.c).
page_address(page) is the virtual address (__va) of
the physical address of the page, computed by adding
(page - zone_mem_map) pages to the physical address of the page zone
(zone_start_paddr). It is defined in include/linux/mm.h
kvirt_to_pa(addr) is repeatedly defined as the physical address
(
__pa) of the
page_address corresponding to the virtual
address addr plus the offset inside x (ie, x & (PAGE_SIZE-1) ),
__pa( page_address( vmalloc_to_page( addr ) ) | offset( addr ) )

Virtual Memory
-
vmalloc_to_page(x) returns the page containing a virtual address.
It traverses the three-layer page table to find the
page containing the given address,
pgd = pgd_offset_k( x ); // pgd_offset( init_mm, x )
pmd = pmd_offset( pgd, x );
pte = pte_offset( pmd, x );
return pte_page( *pte );
First the entry at index x>>PGDIR_SHIFT of the PGD of
init_mm is found.
Next this PGD is returned as PMD,
the middle table being folded on the global table.
Third the PTE entry of PMD at index (x>>PAGE_SHIFT)&0x3ff is
found and the page in mem_map at index (PTE>>PAGE_SHIFT)
is returned.
-
get_vm_area(size, flags) allocates (kalloc) a vm_struct and inserts
it in the list vmlist. It is defined in mm/vmalloc.c
-
vmalloc_area_pages(addr, size, gfp_mask, prot)
gets the pgd and the pmd for addr, and allocates area for the pmd.
-
__vmalloc(size, gfp_mask, prot)
gets a VM area of specified size (get_vm_area), and allocates the pages
(vmalloc_area_pages).
Memory Allocation
References
R. Love, "Allocating memory in the kernel",
Linux Journal, 116, Dec. 2003, 18-23
A. Rubini, J. Corbet, "Linux Device Drivers" (2-nd ed.),
O'Ralley 2001
...
kmalloc is the kernel equivalent of the C library function
malloc,
void * kmalloc( size_t size, int flags )
The extra parameter flags specifies the type of memory allocation,
- GFP_ATOMIC does not sleep;
- GFP_DMA use DMA-capable memory
- GFP_KERNEL the normal case; can block
- GFP_NOFS may block but not initiate a filesystem op
- GFP_NOIO may block but not initiate block i/o
- GFP_USER allocate memory for user-space processes.
Like the C routine
kmalloc can fail and return NULL.
To srelease the memory allocated with kmalloc you use kfree
which is completely analogous to the C library routine free.
kmalloc returns a physically contiguous piece of memory.
The memory allocation is managed with a buddy algorithm that keeps lists
of free blocks of different sizesfrom 512 B to 32 KB [ MUST CHECK ].
When there is a request for some memory the algorithm goes through the
lists to find a free block of the smallest size that can satisfy the
request. If only a big block is available it is split until a block
of the smallest possible size is obtained. The other pieces are put on
the respective free lists.
When a block is returned, the algorithm tries to combine it with its
buddy, if available free, to form a bigger block.
When a large chunk of memory is needed it is better to use
vmalloc,
which returns a virtually contiguous area of memory.
Addresses obtained with
vmalloc are kernel virtual addresses,
and must be handled differently from the addresses obtained with
kmalloc (called physical addresses, although the really
physical addresses are offsetted by a constant).
Memory obtained with
vmalloc must be released with
vfree.
void * vmalloc( size_t size )
void vfree( void * )
vmalloc can sleep, and has a performance overhead, because
the use of TBL for virtual kernel memory is less effective.
[TODO: more about different addresses in the kernel]
The slab allocator
References:
J. Bonwick,
"The slab allocator: an object-caching kernel memory allocator",
USENIX Summer 1994 Technical Conference (1994)
B. Fitzgibbons, "The Linux Slab Allocator",
http://www.cc.gatech.edu/grads/b/bradf/cs7001/proj2/linux_slab.html
Memory is reserved with a buddy allocator that gives memory in chunks
of powers of two of the page sizes.
The slab allocator is an abstraction layer that allocates memory at a
grain smaller than the page units.
It is organized in caches (kmem_cache_t), each cache containing
slabs on which the objects are "allocated".
The
kmem_cache_t struct contains
- list heads for the full, partial, and free slabs. Memory released to the
cache is not relinquished immediately to the buddy allocator, but can
be cached, for efficiency. Therefore there can be partially filled slabs,
and empty slabs.
- the next pointer for the list of caches.
- the name of the cache, for human readable purposes (try
less /proc/slabinfo).
- the size of objects in the cache and their number.
- the cache flags. These include
SLAB_HWCACHE_ALIGN, SLAB_NO_REAP, SLAB_CACHE_DMA
(almost self-explanatory).
- the object constructor ctor and destructor dtor.
These have signature void (*)(void *, kmem_cache_t *, unsigned long)
where the first argument is the pointer to the memory for the object,
the second points to the cache, and the last is the flags.
Objects are stored on slabs, therefore allowing a better use of the pages
of memory. There is some slab maintenance information (the slab_t
struct and kmem_bufctl_t array which follows it). Depending on
its size and the size of the objects, this is put either on the slab itself
(at the beginning) or off-slab (in a memory cache).
Finally if extra space is available, the objects on the slab can be
coloured, ie, put at different address offsets so that to better use
the hardware cache lines.
The slab allocator has functions to create/destroy a cache, and
allocate/free objects.
- kmem_cache_create(name, size, offset, flags, ctor, dtor)
creates a cache, and adds it to the cache list.
The name is the human readable name of the cache.
size is the objects size, and offset is the colour.
- kmem_cache_destroy(cache_p, flags) deletes the cache,
removes it from the cache list, delete all the slabs, and frees any
per CPU caches.
Other functions are
kmem_cache_grow( cache_p, flags ) (used to allocate memory for a
slab, initialize the objects on the slab, and add the slab to the cache),
kmem_cache _shrink( cache_p ) (which deletes the objects from the
per CPU caches, and deletes the free slabs), and
kmem_cache_reap( gfp_mask ) (used by kswapd to reap the cache
in the cache list).
The
slab_t struct is rather short,
- list to link the slabs on the cache together;
- colouroff the colour offset of the slab;
- s_mem the memory address of the first object on this slab;
- in_use the number of objects in use in this slab;
- free, an array of kmem_bufctl_t struct which is stored
immediately after the slab.
The relevant slab functions are
- kmem_cache_alloc(cache_p, flags)
return a pointer to the object or NULL.
flags is the same flags usable for kmalloc(),
ie, SLAB_ATOMIC (use in interrupt), SLAB_USER (use in user space),
SLAB_KERNEL (use in kernel space).
- kmem_cache_free(cache_p, obj_p)
takes a pointer to the cache and a pointer to the object to free.
Exercise
Marco Corvi - 2003