MULTILAYER PERCEPTRON
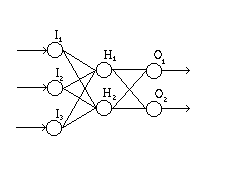 Multilayer perceptron (MLP) is a neural network whose nodes are
organized into layers.
A 3-layer network has the generalization properies of a
many layer one, therfore we will consider oa 3-layer network
with an "input" layer, a "hidden" layer, and an "output"
layer (see figure).
Multilayer perceptron (MLP) is a neural network whose nodes are
organized into layers.
A 3-layer network has the generalization properies of a
many layer one, therfore we will consider oa 3-layer network
with an "input" layer, a "hidden" layer, and an "output"
layer (see figure).
The MLP is a function that maps a N-dimensional input vector
to a M-dimensional output vector.
The input vector components are fed to the input nodes and
the output vector components are read from the output nodes.
The MLP can be used for classification and for interpolation
problems.
As classificator task the output components can represent
confidence of belongingto one of M classes.
As interpolator the output components represents the
coordinate of a point in M-dim space.
For a given input vector I, the output vector
O is obtained by propagating the input
through the network.
The value at the input nodes are determined by the
values of the input vector components.
The values of the hidden nodes are determined according to
|
Hj
| = |
g( P'j )
|
| | = |
g( ∑i W'i,j Ii - T'j )
|
where g(x) is an activation function that is monotonic increasing,
and has limits 0 and 1, as x goes to neg. infinity and pos. infinity,
respectively.
For example, g may be the "sign" function,
or the "sigmoid" function (T denotes the temperature:
when T goes to 0 the sigmoid tends to the sign function)
g(x) = 1 / ( 1 + exp(-x/T) )
The matrix W' is the weight of the connections
between the input and the
hidden nodes, and the vector T' are the thresholds.
The thresholds can be considered as the 0-row of the weight matrix,
corresponding to constant inputs with value -1.
A similar rule is used to propagate the node values from the hidden
to the output layer. We denote the linear combination of the
hidden values
P"k
= ∑j W"j,k Hj - T"k
Training
The MLP needs to be trained on examples consisting of input-output
pairs, (I*, O*).
The training aims to minimize the error between the network
outputs and the training outputs (an alternate point of view consists
of minimizing the energy which is just the error):
E = 1/2 ∑k [
Ok - Ok*
]2
where Ok=g(P"k).
The weights and the thresholds are changed so that to reduce the
error:
|
dE/dW"j,k | = |
Hj dE/dP"k
|
| | = |
Hj ( Ok - Ok* ) g'( P"k )
|
|
dE/dT"k | = |
(-1) dE/dP"k
|
| | = |
(-1) ( Ok - Ok*) g'( P"k )
|
For the connections between the input and the hidden layer we have
|
dE/dW'i,j | = |
Ii dE/dP'j
|
| | = |
Ii ( ∑k W"j,k dE/dP"k ) g'( P'j )
|
|
dE/dT'j | = |
(-1) ( ∑k W"j,k dE/dP"k ) g'( P'j )
|
The errors are thus backpropagated through the network.
The training algorithm is therefore
- initialize the weights and the thresholds randomly;
- given a pair (I*, O*)
propagate the input through the network;
- compute the error Ok - Ok*;
- backpropagate the error (to the hidden layer);
- adjust the connections proportionally to the derivatives of the
error computed above.
Marco Corvi - Page hosted by
geocities.com.